Agentic AI no Power BI e Fabric: O que é e por que importa
Agentic AI está mudando a forma como trabalhamos com Power BI e Microsoft Fabric. Se você atua com dados, já…

O Microsoft Fabric é uma plataforma baseada em nuvem que oferece uma experiência unificada de ciência de dados, engenharia de dados e inteligência de negócios. Assim, ele fornece uma variedade de recursos e serviços, como preparação de dados, aprendizado de máquina e visualização. Ou seja, o abrangente conjunto de ferramentas do Fabric permite que profissionais de dados e usuários de negócios desbloqueiem todo o potencial de seus dados e moldem o futuro da IA.
Neste blog, nosso foco será nos serviços de ciência de dados do Fabric, mostraremos como usar o Microsoft Fabric para construir um modelo de previsão e exploraremos as notáveis ferramentas do notebook.
Primeiramente, para acessar o Microsoft Fabric, crie uma conta em app.fabric.microsoft.com para uma avaliação gratuita ou, se você já for um cliente do Power BI, poderá entrar usando as credenciais da sua conta do Power BI.
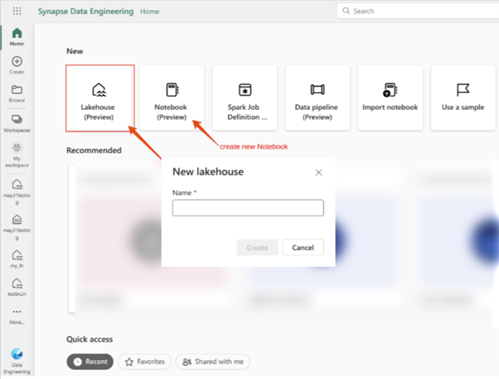
Quando nos referimos a dados, podemos falar sobre o armazenamento de dados estruturados e não estruturados. Então, o Lakehouse da Fabric é um dos objetos que podem armazenar dados e é uma plataforma de arquitetura de dados para gerenciamento e análise de dados. Assim, ele tem a capacidade de se expandir e se adaptar para gerenciar grandes quantidades de dados e oferece suporte a vários tipos de ferramentas e estruturas de processamento de dados. Para saber mais sobre o Data Lakehouse, consulte O que é um lakehouse no Microsoft Fabric?
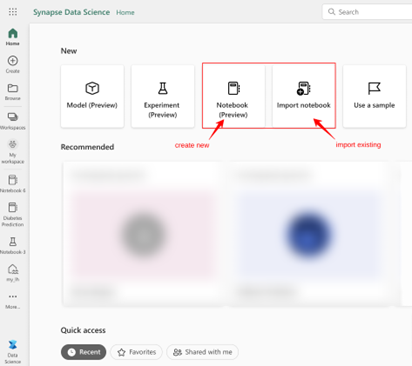
O Fabric utiliza o artefato de notebook dentro da experiência de Data Science para demonstrar os diversos recursos da estrutura do Fabric. O Fabric permite a utilização de notebooks com a finalidade de desenvolver experimentos de aprendizado de máquina e facilitar sua implantação. Portanto, o serviço Data Science e o notebook fornecem uma ampla gama de recursos, que serão discutidos mais adiante. Você pode consultar este Como usar notebooks do Microsoft Fabric para saber mais sobre os serviços de ciência de dados
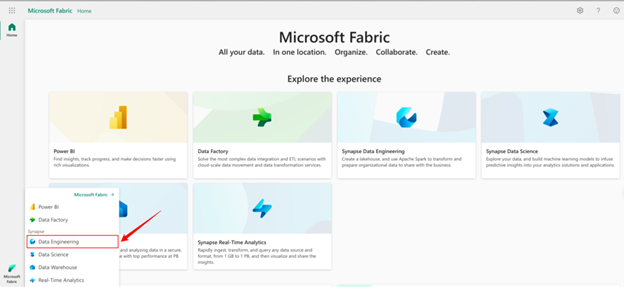
Siga as etapas abaixo para armazenar arquivos/dados no Lakehouse:

Agora vamos ver como podemos treinar nosso modelo para previsão.

Esta seção percorre as etapas envolvidas no treinamento de um modelo Scikit-Learn, incluindo o processo de salvar os modelos treinados. Além disso, demonstra como utilizar o modelo salvo para previsões quando o procedimento de treinamento estiver concluído. Para saber mais sobre os modelos no Fabric, consulte Como treinar modelos com o scikit-learn no Microsoft Fabric .
Observe que o código fornecido nesta seção foi projetado especificamente para o Microsoft Fabric Notebook. Ou seja, tentar executar o código em outras plataformas, como Colab ou qualquer outra plataforma, pode resultar em erros. Isso ocorre porque a função PREDICT utilizada no código exige que os modelos sejam salvos no formato MLflow, que é suportado principalmente pela linguagem Spark.
import mlflow
mlflow.set_experiment("Prediction")Ele criará um novo experimento chamado “Prediction” em seu espaço de trabalho. Contudo, você pode verificar as experiências de aprendizado de máquina no Microsoft Fabric para saber mais sobre “Experiência”.
Ou você pode criar um experimento usando a interface do usuário (no seu espaço de trabalho, selecione o experimento no menu suspenso).
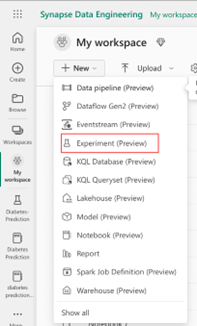
No código abaixo, escreva o nome do modelo em mlflow.sklearn.log_model()
import mlflow.sklearn
from mlflow.models.signature import infer_signature
mlflow.set_experiment("Prediction")
with mlflow.start_run() as run:
model = LGBMClassifier(random_state = 12345)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
score = model.score(X_train, y_train)
signature = infer_signature(X, y)
print('score…:',score)
print('Accuracy…:',accuracy)
mlflow.sklearn.log_model(
model,
"model",
signature=signature,
registered_model_name="model"
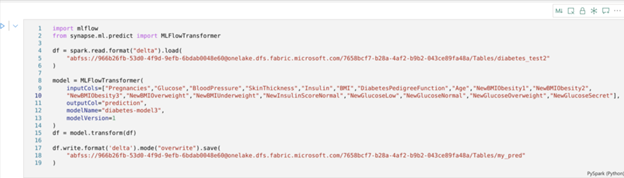
)from pyspark.sql import SparkSession
from synapse.ml.predict import MLFlowTransformer
spark = SparkSession.builder.getOrCreate()
test = spark.read.format("csv").option("header","true").load("Files/test.csv")
display(test)
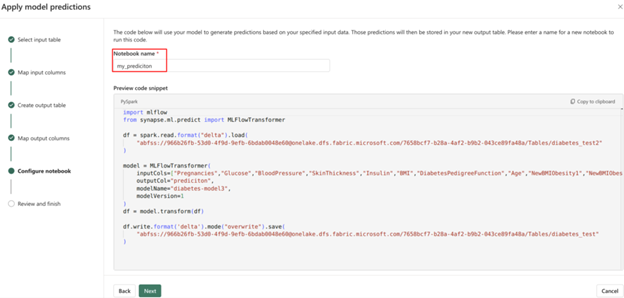
model = MLFlowTransformer(
inputCols=test.columns,
outputCol='predictions',
modelName='diabetes-model',
modelVersion=1
)
prdiction = model.transform(test).show()
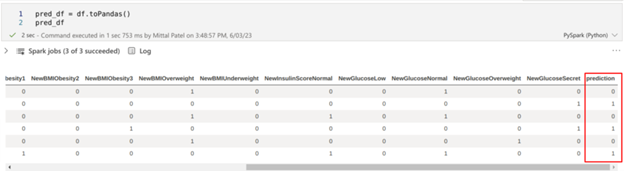
pred_df = prdiction.toPandas()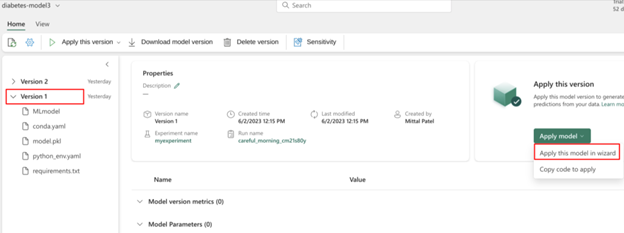
Dessa forma, você pode usar o Fabric Notebook para seus experimentos de ciência de dados.
Veja também nosso artigo Microsoft Fabric: Definição e recursos.

Agentic AI está mudando a forma como trabalhamos com Power BI e Microsoft Fabric. Se você atua com dados, já…

Quando se fala em Copilot, muita gente ainda associa apenas a geração de texto ou ajuda na criação de fluxos.…

O Copilot dentro do Power Automate não muda o que a ferramenta faz. Ele muda como você começa um fluxo.…
 /trinapse
/trinapse