Transformando o SharePoint em um sistema inteligente com Power Platform
O SharePoint é uma poderosa ferramenta de colaboração e armazenamento de dados, amplamente adotada para gestão de documentos e trabalho…

Nesta postagem, mostramos como você pode usar o Power Automate para converter páginas modernas do SharePoint em arquivos PDF e salvá-los em uma biblioteca de documentos.
O que você precisará
Nota sobre a biblioteca de páginas do site
No meu exemplo, eu não queria que todas as páginas do site fossem convertidas em arquivos PDF, então adicionei uma coluna de escolha para ‘marcar’ todas as páginas que deveriam ser convertidas. Eu defino o valor padrão da coluna de escolha como ‘Página do site’, para que as únicas páginas convertidas sejam aquelas em que estou interessado. Isso se reflete no fluxo abaixo com a etapa de condição.
A ação do gatilho para nosso fluxo é quando um arquivo é criado ou modificado (somente propriedades) Isso nos permite executar novamente o fluxo quando as páginas do SharePoint são atualizadas para também atualizar os arquivos PDF.
Em seguida, adicionei uma condição para converter apenas as páginas marcadas como ‘Runbook’ em PDF.
Se sim, a próxima é enviar uma solicitação HTTP para a etapa do SharePoint. Aqui estou usando uma chamada de API REST para obter o conteúdo do corpo da página do SharePoint.
Usei a etapa de análise JSON para remover a marcação indesejada e apenas obter o texto simples do conteúdo do corpo.
Em seguida, pressionei gerar a partir da amostra, que gerou o seguinte
{
"type": "object",
"properties": {
"d": {
"type": "object",
"properties": {
"CanvasContent1": {
"type": "string"
}
}
}
}
}A partir disso, usei uma ação de criação de arquivo para criar um arquivo HTML temporário no OneDrive, com a seguinte configuração:
Em seguida, uma etapa de conversão de arquivo para converter a página HTML em um arquivo PDF:
Agora podemos usar uma ação de criação de arquivo para criar um PDF em nossa biblioteca de documentos de saída no SharePoint:
Em seguida, usei uma ação de atualização de propriedades do arquivo para passar metadados da biblioteca de páginas do site para a biblioteca de documentos de destino – esta etapa é opcional. Por fim, uma ação de exclusão de arquivo para excluir o arquivo HTML temporário do OneDrive que criamos anteriormente.
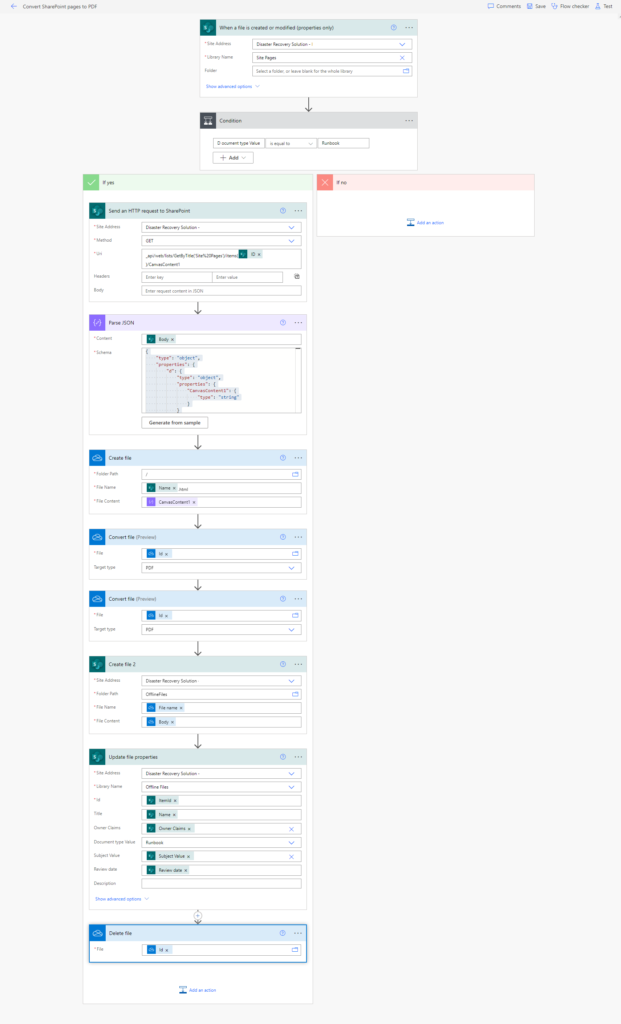
Aqui está o fluxo na íntegra:
Problemas de formatação com o envio de uma solicitação HTTP para o SharePoint
Conforme mencionado acima, ao usar apenas a ação enviar uma solicitação HTTP para o SharePoint, a saída contém marcações que não farão sentido no PDF. A ação parse JSON limpa isso e apenas deixa o conteúdo do corpo da página.
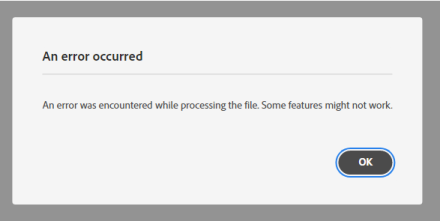
Ao testar esse fluxo, originalmente não tinha a ação converter arquivo em vigor. No nome do arquivo eu adicionei ‘.PDF’, mas toda vez que o PDF de saída estava corrompido e com erro assim ao tentar abrir:
O fluxo também falhou nesta etapa e o erro dizia que “A conversão deste arquivo para PDF não é suportada. (InputFormatNotSupported / pdf)” . Decidi descartar essa abordagem e criar uma página HTML e adicionar a ação de converter arquivo que resolveu esse problema.
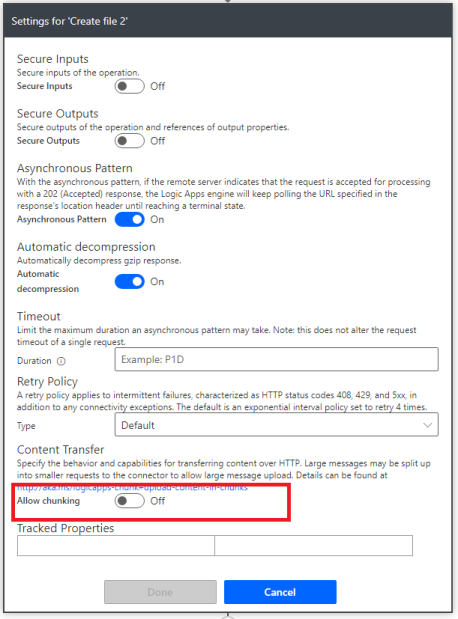
Durante o teste desse fluxo, também notei que, ao acionar o fluxo com base na atualização de uma página do site, a ação de criar arquivo criar arquivo apresentaria um erro de status 400 dizendo “Já existe um arquivo com o nome [nome do arquivo]” .
Para mais conteúdos como este continue acessando o blog da Trinapse.

O SharePoint é uma poderosa ferramenta de colaboração e armazenamento de dados, amplamente adotada para gestão de documentos e trabalho…
")
O SharePoint Framework (SPFx) é um modelo de desenvolvimento baseado em cliente que permite criar soluções modernas e personalizadas para…
 é essencial")
À medida que as organizações adotam cada vez mais o SharePoint Online para soluções de ambiente digital, a necessidade de…
 /trinapse
/trinapse